
CogniFit incorpora la tecnología de AWS para simplificar, agilizar y potenciar nuestros datos
Desde el principio, CogniFit ha sido muy consciente de la importancia de utilizar buenos datos. Nuestras herramientas de evaluación y estimulación cognitiva se conceptualizan, planifican y desarrollan teniendo en cuenta datos científicos precisos, lo que ha permitido que nuestra plataforma crezca hasta convertirse en una herramienta utilizada no solo por personas de todo el mundo que quieren darse a sí mismas o a sus seres queridos un impulso cerebral, sino también por profesionales de la educación y la sanidad que necesitan una potente plataforma para evaluar, hacer un seguimiento y entrenar las capacidades cognitivas de sus alumnos y clientes.
Pero esa no es la única forma en que CogniFit crea valor a través de los datos. La enorme cantidad de datos generados por nuestra plataforma puede ser utilizada también por los investigadores científicos, proporcionando una fuente única de información sobre las capacidades cognitivas y cómo estas capacidades juegan un papel integral en todo lo que hacemos. CogniFit ha optado por utilizar la plataforma de Amazon Web Service para crear un valioso ecosistema de datos, lo que nos permite simplificar nuestros procesos de almacenamiento de datos, agilizar la forma en que utilizamos e interactuamos con nuestros datos, y potenciar nuestra capacidad de crear valor a partir de los datos para nuestros clientes y nuestros socios de investigación.
Cómo CogniFit utiliza Amazon Web Services para aportar aún más valor a nuestros datos cognitivos
Elegimos utilizar la plataforma AWS de Amazon como parte fundamental de nuestra infraestructura de datos por la potencia y la relativa sencillez de su plataforma. Estos son algunos ejemplos de cómo utilizamos AWS:
Simplificación del almacenamiento de datos
Los datos físicos de CogniFit se dividen en dos bases de datos principales que mantienen separada la información personal utilizada para aplicaciones como el registro en nuestro sitio web y la realización de pagos de los datos creados por nuestras aplicaciones que incluyen información que podría indicar, por ejemplo, el estado de salud física o mental de un usuario.
Aunque existen múltiples razones para la organización de nuestro almacenamiento físico de datos, la privacidad de nuestros usuarios es primordial entre ellas. Sin embargo, puede haber ocasiones en las que necesitemos comparar datos que podrían residir en una base de datos, como la capacidad de un usuario para enfocar visualmente un único estímulo, con datos de otra, como la edad.
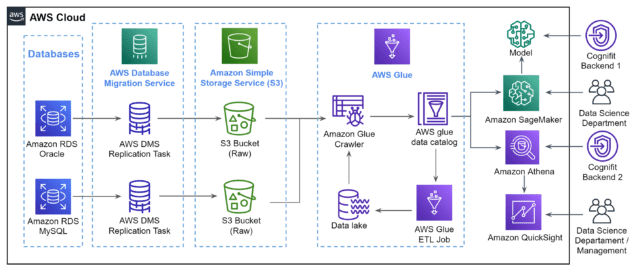
Al utilizar el servicio de migración de bases de datos de AWS para crear depósitos de datos en el servicio de almacenamiento simple, podemos crear una “caja de arena” de datos sencilla y segura en la que podemos manipular nuestros datos sin poner en riesgo la información de nuestros usuarios.
Además, utilizamos el servicio RDS (Relational Database Service) de Amazon para ayudarnos a simplificar la gestión de nuestras bases de datos. Al utilizar AWS EC2 (Elastic Compute Cloud) para alojar nuestros servidores Front-End, podemos aprovechar las potentes funciones de equilibrio de carga y autoescalado para adaptar nuestro sistema a las demandas de tráfico variables a lo largo del día, lo que significa que podemos ofrecer sin problemas a nuestros usuarios un rendimiento máximo durante los periodos de alto tráfico sin desperdiciar recursos del servidor durante los periodos de bajo tráfico.
AWS no solo nos proporciona fantásticas herramientas para crear un plan de almacenamiento de datos potente, eficiente y flexible, sino que, gracias al WAF (Web Application Firewall) de Amazon, podemos garantizar que nuestras aplicaciones web están a salvo de las amenazas online.
Optimización del procesamiento de datos
Con las herramientas de datos como AWS Glue, podemos refinar, filtrar y procesar los datos de formas nuevas y potentes, lo que nos permite convertir los datos brutos en información organizada y valiosa.
La creación de bases de datos virtuales mediante herramientas como AWS Glue Crawler y AWS Glue ETL Jobs nos permite construir fuentes de datos sencillas pero potentes para una variedad de aplicaciones internas y externas.
De este modo, podemos construir bases de datos individualizadas, diseñadas específicamente para satisfacer los requisitos de cada aplicación de datos.
Supercarga del análisis de datos
Por supuesto, los datos -incluso los perfectamente organizados- no valen nada si no somos capaces de entenderlos y ver las historias que intentan contar. Ahí es donde entran en juego herramientas de AWS como SageMaker, Athena y QuickSight.
Las herramientas de AWS Glue nos ayudaron a convertir los datos en información, pero estas herramientas nos ayudan a convertir la información en conocimiento.
SageMaker está dando a nuestro departamento de informática y a los equipos de desarrollo de software la capacidad de crear recomendaciones hiperpersonalizadas y ajustar la complejidad y la dificultad de las tareas cognitivas sobre la marcha para ofrecer a nuestros usuarios la mejor experiencia y los mejores resultados posibles.
Además, la información de negocio procedente de QuickSight nos ayuda a entender nuestro negocio como nunca antes, arrojando nueva luz sobre los comportamientos y necesidades de nuestros usuarios.
Pero la recopilación y el procesamiento de datos es sólo una parte de cómo creamos un valor increíble para nuestros socios y clientes. Nuestra prioridad es ofrecer soluciones potentes basadas en nuestros datos cognitivos únicos.
La CDN Cloudfront de Amazon nos permite entregar datos, aplicaciones y API a nuestros socios investigadores y desarrolladores a nivel global con baja latencia y alta velocidad de transferencia, así como entregar herramientas de entrenamiento y evaluación cognitiva atractivas y desafiantes a nuestros clientes de forma segura, efectiva y rápida.
Conclusión
Amazon Web Services nos ha permitido impulsar nuestros datos aún más que antes. La integración de herramientas como Simple Storage Service, AWS Glue Crawler y SageMaker en nuestra infraestructura de datos ha desbloqueado un nuevo potencial para nuestros datos.